
REST has been ruling the API industry for a long while now. One of the reasons why REST has been so successful is that REST is highly optimized for servers.
But for a long time, we have been focussing on creating APIs which are highly optimized for servers and not clients. GraphQL lets you build APIs which are more client-centric than ever.
Since REST has been popular for a while now, I will be using comparisons with REST throughout this read for a better understanding.
What is GraphQL?
GraphQL which stands for Graph Query Language is a query language specification for APIs. Since it is a query language, there is only one endpoint for a GraphQL API which always accepts POST requests. These POST requests contain the query for retrieving data. Now, these queries can help you not only read but also modify data(via mutations), buts let’s park that for later.
GraphQL is a strongly typed specification which lets you define a schema for your data. Since the schema is typed into the API implementation, GraphQL is also self-documented.
GraphQL is a standard/specification and not a tool. Therefore you cannot download GraphQL but only use it. You can find GraphQL implementations in almost all popular programming languages here.
Why are we talking about it?
What makes GraphQL so different from REST is its ability to retrieve data on demand and to have relational objects. One can define the relationships between different objects in a GraphQL schema.
While writing a GraphQL query, just like writing a SQL query, the caller can retrieve only the data fields he wishes to and it’s nowhere close to the complexity of a SQL query. Trust me, if writing SQL queries is like graduation, GraphQL queries are like kindergarten. Maybe the word query is just making it look a bit complicated, but all a GraphQL query is, is an object with data field names, which looks somewhat like JSON. We will explore that in the later portions of this read.
Understanding with an Example — Solving the N+1 problem
Now the question would be “How does this make a difference?”. Let’s try understanding it with an example of a Netflix API that I have made.
Let take a use-case where we need to retrieve a movie, all the actors in it, their details and other movies done by these actors. In a traditional REST world, we would need to hit multiple resources to achieve this.
First would be ‘/movies/{movieId}’ to get a particular movie might have a response like this:
{
"id": "5e343369e532731d7bec665c",
"title": "3 Idiots",
"description": "College life of Farhan, Rancho and Raju",
"dateAdded": "26-Jul-13",
"releaseYear": "2009",
"rating": "2",
"country": "India",
"actors":["5e343303e532731d7bec5f0a",
"5e34992kkchhs882mmchsiol",
"5e343kcc8skkskdfhh3999sa"]
}
Second, IDs of all actors returned from the first response needs to be used to get details of actors at ‘/actors/{actorId}’. Response from this resource may look like this:
{
"id": "5e343303e532731d7bec5f0a",
"name": "Aamir Khan",
"age": 54,
"dob": "14-Mar-1965"
}
Third, hit the resource ‘/actors/{actorId}/movies’ to get all the movies the actor has done. This might look like this:
{
"actorId":"5e343303e532731d7bec5f0a",
"movies":[{
"title":"Andaaz apna apna"
},{
"title":"Taree Zameen par"
}{
"title":"Gulaam"
}]
}
Now let’s try to evaluate how many API calls we need to make given that there were three actors in this movie.
--------------------------------------------------
| RESOURCE |Number of Calls |
--------------------------------------------------
| /movies/{movieId} | 1 |
| /actors/{actorId} | 3 |
| /actors/{actorId}/movies | 3 |
--------------------------------------------------
This requires a total of 7 API calls to different resources. Now, this can be reduced to a single API call in GraphQL. A GraphQL query to retrieve all the above data in one shot would look like this:
{
movie(id:"5e343369e532731d7bec665c"){
id
title
description
dateAdded
releaseYear
rating
country
actors{
id
name
age
dob
movies{
id
title
}
}
}
}
Data returned from the above query will be in JSON and of the same format as the query.
Passing values while querying a GraphQL API is done by arguments. Like in the above example, movie id is passed as:
movie(id:”some_value”){}
This helps in implementing pagination by passing offset and limit in arguments.
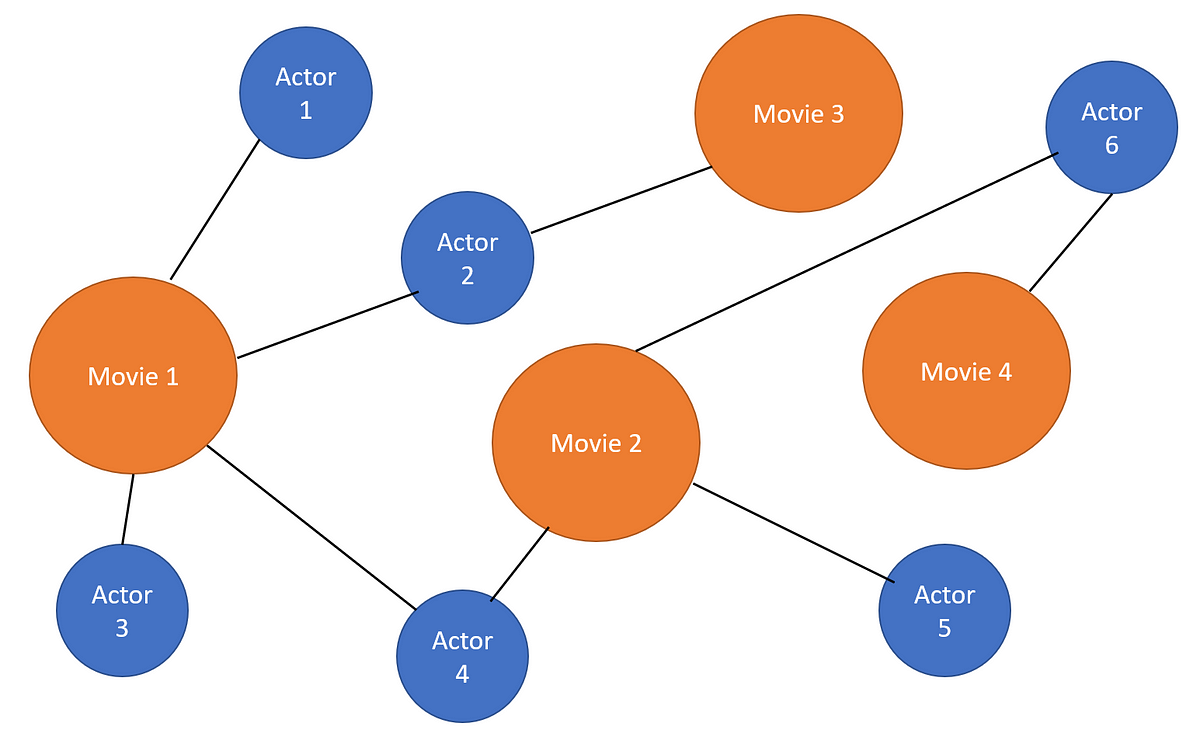
The most interesting part is how all different nodes are linked to each other. Coming from the above example we can see that every movie is linked to all its actors and each actor is linked to every movie they have been a part of. This is fairly represented in the diagram below.
Modifying Data
Till this point, we have been talking about querying data using GraphQL, now let briefly understand how to modify data in GraphQL. Since a GraphQL API has only one endpoint, data modification also happens via the same POST endpoint.
Data modification or insertion is done by calling a function which more or less looks like a GraphQL query. These are called mutations. Mutations let you pass data as arguments. An example will help understand better.
mutation {
addActor(name:"Brad Pitt", age: 55){
id
name
age
}
}
Here addActor is a mutation and name & age are arguments containing data to be inserted. Three fields inside curly brackets of addActor tell GraphQL which fields to return if data insertion was successful.
Advantages
GraphQL helps maintain relations between different object types which makes querying recursive data easier.
Since data retrieval in GraphQL is done using a query, the caller can retrieve fields on demand.
For all the operations in GraphQL, there is a single end-point which is usually /graphql. This simplifies the design as all operations(CRUD) can occur through this single end-point.
Every GraphQL API has a schema for all the object types defined in the implementation. This schema is the contract for a user to interact with the API. Since the schema is already defined, GraphQL endpoints are self-documented.
GraphQL has an interactive UI for trying out GraphQL APIs called GraphIQL. This is inbuild in all GraphQL libraries for all languages. This UI has the documentation for all the queries and since the schema is already declared, inteli-sense is enabled.
Limitations
GraphQL by default has no in-built provision for authentication and authorization. For authentication, the user might have to hit some other authentication endpoint or authentication has to be handled by the web-server/proxy layer. Then the GraphQL endpoint will be able to accept the Authorization token.
Similar to authentication, there is not out of the box provision for authorization. It is recommended to handle authorization at the controller lever rather than doing it at GraphQL layer. It can become complicated to handle authorization in GraphQL.
GraphQL does not provide segregation of features like REST. Everything is mixed up in a single endpoint.
Although GraphQL has a strongly typed schema, it can be pretty confusing to understand the endpoint. REST has very clear segregation with resources and inbuilt documentation written in the APIs contract(Swagger, RAML, etc.). End-user might have difficulty in understanding where to get started.
Wrapping it up
GraphQL is a modern API specification which helps build APIs which are client-centric. This API design helps return all the data in one API call which is helpful for mobile applications trying to get data over limited network bandwidths by reducing the number of API calls. e.g accessing your Facebook posts over a 2G connection. GraphQL is increasingly becoming popular. To try out GraphQL, you can try GitHub API implementation in GraphQL here.
GraphQL can enable you to get all the data you want in one API call, but GraphQL is not the first thing to do so. There have been FAT APIs for a long time now which deliver all the content at once. The advantage that GraphQL presents is you can alter the structure of data you receive depending on your query.
Note
Not all old things need to be replaced. However tempting it might be for you to go ahead and change your API implementation from REST to GraphQL, don’t do it right away. Analyze if your requirements need you to migrate to GraphQL. It has its own disadvantages which might not be beneficial for you. Make sure you are making a choice by giving some due thought.
Also, you can find the code of the example Netflix API mentioned in this read here.
End Note
Hope you found this article interesting, do drop us a comment below with your inputs, views, and opinions regarding GraphQL: Next step towards building a client-centric API.
Also, if you are interested in learning more about an exciting new code quality product that reduces your Mule project costs by upto 80%, follow the below link :
Discover more from Integral Zone
Subscribe to get the latest posts sent to your email.






