Mulesoft is an industry leader in the API management and iPaaS segment. An increasing number of companies are working with Mulesoft products for all their integration needs. This means more and more APIs and integration implementations are added into the enterprise’s backlog.
But what about MuleSoft Code Quality?
Since we use an industry leading integration provider, are further code quality checks needed?
Mulesoft doesn’t enforce standards
Mulesoft is a great tool which can help accomplish many of the things you want to do. You want to connect Salesforce to ServiceNow, you can do it. Connect SAP to custom applications – sure you can. You want Cloud to on premise connectivity – you can do it with ease. What about security, reliability, maintainability and other such vital quality factors though?
Let’s take a security example:
Mulesoft provides multiple ways to connect to Salesforce:
- Basic authentication (username, password, token)
- OAuth authentication
- OAuth with SAML SSO

Mulesoft Salesforce Connector – Authentication Options
You can store the sensitive information like authentication credentials in the code itself, in configuration files in the Mule source code or in external systems.
Your code will work using any of the above methods. However, as an organization you would not want the code to be stored in plain text format or maybe as unsecured configuration files. You would even not want to allow basic authentication to happen for a particular system without secure means!!
Let’s take a reliability example:
Mulesoft provides an easy way to call external web services or APIs. Drag and drop – and it’s done. Let’s say you now want to enable retry configuration on the external call by invoking a Web Service three times before you give up in case of error. Furthermore, you may want the process to consistently keep trying to call an external system successfully until it manages to get successfully get through.
When there is a requirement to connect to an external system, it could be implemented in any of the formats stated above.
But, from an organization’s perspective, you don’t want to allow these multiple options.
Also, let us assume the organization wants to ensure whenever you are connecting to an external system, they can retry three times before backing off, they can keep trying till it succeeds?
Maybe also send out an email or notification whenever the error occurs.
How do you enforce this kind of standard?
Manual checks are not the answer
The usual process of code quality in a Mulesoft implementation are as follows:
- Create developer guidelines (and tons of them at that) and share with the community somewhere (either in some word document or a wiki page)
- Make sure the document is read and whenever someone comes to the project as a new member, make sure that they go through the documentation
- Code will be written by developer and goes through the Dev Sec Ops process
- Before go live, have the code reviewed by an architect as part of sanity check
- If the code quality check goes through, let it get deployed to production
Sounds familiar?
Almost always, in the organizations we have seen implementations go through steps 1-4. Finally we end up finding issues at step 4.
The project is supposed to go live in the next day/week – and you find issues – what do you do?
Answer – Give an exceptional go ahead to deploy to production and slot in the fixes to be added by the next version or iteration.
Hence the next iteration is delayed/cancelled as more pressing integration requirements have come to the team to solve.

Issues with manual code review and code quality
Result: You have unsecured, non-compliant code which has gone live and your technical debt is building up.
Inevitably, when an incident occurs in production, you do a quick fix, blame the quality process and move on…
Good Mulesoft code quality should enable the developers not hinder them
When a new developer is on boarded onto a project, they are bombarded with a lot of documentation. Even more in a Mulesoft implementation, the content will end up becoming overwhelming. Death by documentation! What we need is an easy way to induct the developer and provide indications when they are performing development actions which are not allowed in the organization.
Let us take the same security example as earlier:
Developer wants to connect to Salesforce and he drags and drops the Salesforce connector into the design area. He gets a prompt in the studio which states that he should always connect only using OAuth Authentication. This is due to it being the only approved way to connect to Salesforce in the organization!

IZ Analyzer showing custom rule for organization about approved authentication approach for connecting to Salesforce
Also, imagine he is trying to store sensitive information in plain text format in a properties file. Hence he gets a prompt stating “sensitive information should be encrypted before storing within the source code.”
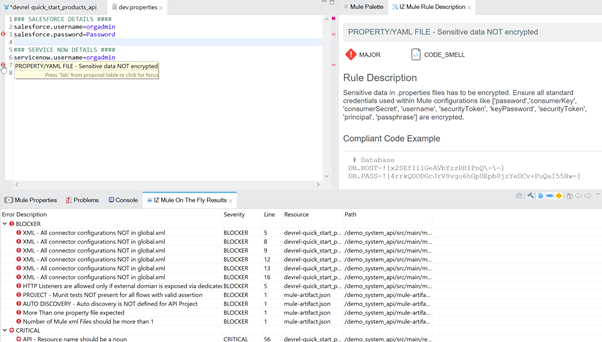
With readily available information at their fingertips, a developer would be able to make sure from the second they starts designing the integration that what they are trying to do is compliant to enterprise standards and the right way to implement the solution.
Mulesoft Code quality should be an essential part of Dev Sec Ops – not an afterthought
Every commit into the source control system, every pull request, every configuration change or code change should go through the rigorous code quality process. Sounds like overkill, especially with all the effort involved in doing the code quality checks in a traditional world. But what if we could automate the entire process? The Developer has already developed code that is in conformance with organization standards, but to prevent rogue commits going through the SDLC we can automate the code quality throughout the life cycle. Whenever the code is committed into the repository, we run an automated code quality check whenever a branch is merged, pull request created. Alternatively, you can schedule periodic automated code quality checks to run.
Automated code quality finds out all the non-compliant issues within the code implementation. Also, it will generate ratings for the code, tells you what severity of issues needs to be dealt with and whether it passed or failed the quality gate process.
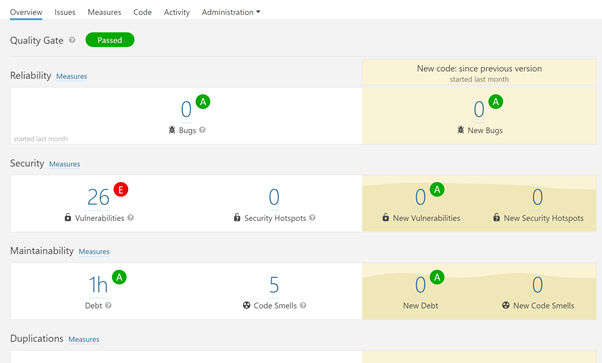
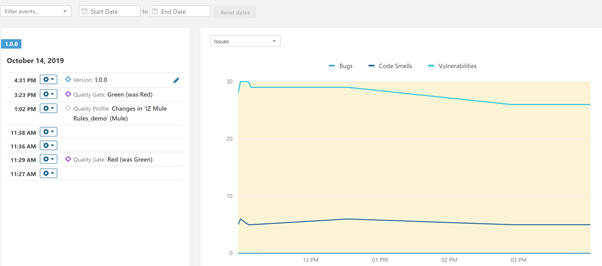
You get a detailed report tracked throughout the Dev Sec Ops process – to help understand the quality of the code going through the pipeline.
Final thoughts
Mulesoft Code quality means different things to different people. What Management looks for from code quality will be significantly different from what a developer understands.
As long as Mulesoft code quality process remains manual and documentation oriented; the gap will continue to increase and it will continue to be ineffective in real world implementations.
In an API and microservices world – especially with security & reliability issues impacting brand and incurring financial penalties – it is extremely important to make sure Mulesoft code quality is paramount to the organization – perhaps it should even be the number one priority!
IZ Analyzer was used in the article to showcase the automated Mulesoft code quality – since these are the principles based on which the products are built.
Start using IZ Analyzer for Free
Interested in trying out the most powerful MuleSoft code review tool in the Mule Ecosystem? Click below to start using IZ Analyzer for free
Discover more from Integral Zone
Subscribe to get the latest posts sent to your email.






